
AIOPS + Automation: Re-Inventing the IT Automation Playbook
Read more about from AIOPS + Automation series:
Part i
The promise of AI/ML use cases in IT Ops and DevOps teams is centered on increased automation with minimal maintenance. The return on investment for Vanilla Runbook Automation (RBA), IT Process Automation (ITPA), and Robotic Process Automation (RPA) is limited by network effects.
In any rules-based automation system, each logical step is preceded by a conditional statement (if, then, etc.). These conditionals can be represented as a graph of potential paths through the workflow. Each new graph and each conditional connection between workflows, gives rise to more points at which a change in the underlying systems might break the validity of any assumptions embedded in that point in the workflow.
This post is a 4 part series that explores how AI and machine learning can change the playing field with regards to IT automation, and drastically increase the amount of automation that an organization can deploy in their environment.
Part I: The Current IT Automation/Runbook Automation Playbook
IT Automation can be divided into four major categories. To begin, request-driven automation is any user-initiated workflow, such as ‘reset my password,’ ‘add a new user to active directory,’ or ‘restart this service on a virtual machine.’ Request-driven automations have the advantage of constrained expertise, in that access to the automation can be restricted to only those personnel who are presumed to have the training and/or tribal knowledge to determine when the automation is appropriate to use, and what action to take once the automation succeeds or fails to complete the desired end result. The main issue with constrained automation is that the constraint imposes significant limits on the scope of a specific automation.
For example, depending on the application that it supports, the method for restarting a Windows service may differ. As a result, while request-driven automation is useful, it does not account for a significant portion of the overall automation opportunities in IT Ops / IT Service Delivery.

By making the same type of constrained automations event-driven, organizations can drive slightly more automation across IT service delivery and operations. Thereby, simple automations that do not require human intervention can be deployed. This works only if the event’s context can be specified with enough certainty to ensure that the likelihood of error is minimal. For example, an automation that closes a firewall port (e.g., to prevent a DoS attack) should only be used if the risk of negatively impacting customers is minimal, and such consideration must be ‘programmed-in’ to the triggering logic. Such an event might only trigger that automation on the firewall if it was through a time that customers would not be expected to require access to the service.
Diagnostic automations generally have a slightly greater potential impact on operational efficiency. These automations are typically ‘feed-forward,’ meaning they feed directly into a human-centered decision-making process. When troubleshooting a potential incident, for example, several technical specialists will typically log into their respective tools and/or devices, depending on their subject matter expertise and role (network, server, database, security, etc.).
These experts will carry out a series of diagnostic tests, either within a tool or on the command line interface of the suspected devices. All of these steps can be automated and linked to reduce the amount of time it takes to troubleshoot and restore service. These diagnostic automations require some time from each subject matter expert, and the decision on when to apply a specific diagnostic automation or health check varies widely depending on the type of incident and upstream services.
Self-healing automations are workflows that are triggered by an event and are intended to fully restore a service to normal operating conditions or to prevent a service disruption from happening. The traditional approach to designing these self-healing automations is to initiate a diagnostic automation to narrow down likely causal conditions, and then apply a step-by-step service restoration/prevention automation. As a result, each of these self-healing automations is quite complex, requiring subject matter expertise from multiple groups and encoding logic that makes deep assumptions about the behavior of the relevant service. The required complexity raises the cost of deploying each such automation while also increasing the incremental maintenance required to test and remediate the automation when the service is changed (i.e. additional capacity is added or a new database architecture is implemented).
Figure 1.3: Diminishing Value of Rules Based Automation as New Automations Are Developed
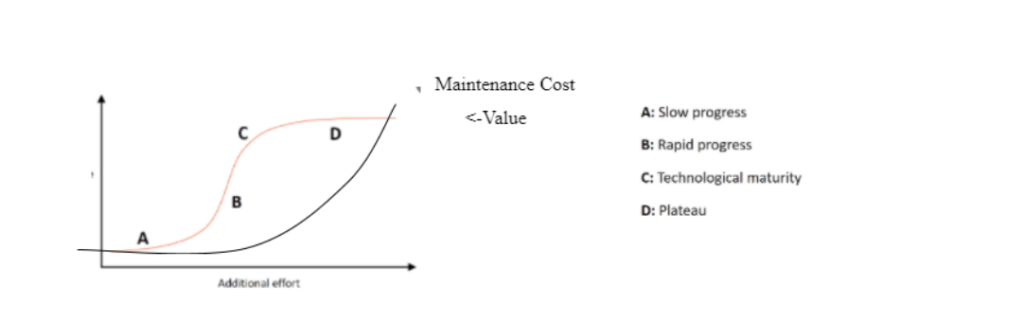
The field of AIOPS arose as a result of the practical difficulty in managing this point of diminishing returns. This barrier can be removed by incorporating machine learning into the overall automation strategy, allowing a much larger portion of the overall automation opportunity to be captured. ML, for example, can perform these tasks automatically by learning the patterns in underlying operational data (logs, events, performance) and their upstream context (is it an incident or just a shift in the system’s behavior that generated some log data?) rather than writing complex diagnostic opportunities to identify an emerging incident and its underlying cause.
These automation types can be thought of as existing on a maturity spectrum. Often, organizations will begin with simple request-driven automation and then invest further up the stack after seeing positive results. The simplest use-cases are applied to levels 1 and 2, but progress slows across levels 3 and 4. Many of the roadblocks to automation initiatives are removed by incorporating machine learning.