
An Introduction to Supervised machine learning & its methods
We discussed unsupervised machine learning in our previous article on the Towards AI blog, and today we will discuss another type of machine learning – Supervised Machine Learning.
Topics covered on this article:
- What is Supervised Machine Learning?
- How does Supervised learning work?
- What are the applications of Supervised Learning?
What is Supervised Machine Learning?
Supervised machine learning helps to train machines using training datasets and then predicting output based on the results. This means that we have to split our dataset in two parts: Training dataset and test dataset. We train our network using the training dataset, whereas the test dataset serves as new data for predicting results or testing our model’s accuracy.
The process of supplying input data as well as accurate output data to the machine learning model is known as supervised learning. Most practical machine learning uses supervised learning, and the process is a supervised learning process when you have input variables (x) and an output variable (Y), where the goal of the function generated by these two variables is to approximate the mapping function at the stage that when new input data (x) are given, then you can predict the output variable (Y) for that data.
Y= f(x)
It is called supervised learning because the process of an algorithm learning from the training dataset can be thought of as a teacher supervising the learning process. We know the correct answers, the algorithm iteratively makes predictions on the training data and is corrected by the teacher. Learning stops when the algorithm achieves an acceptable level of performance.
Supervised learning problems can be further grouped into regression and classification problems.
Classification: A classification problem is when the output variable is a category, such as “red” or “green” or “disease” and “no disease”. Listed below are some popular algorithms under classification algorithms:
- Decision Trees
- Random Forest
- Logistic Regression
- Support vector Machines
Regression: A regression problem is when the output variable is a real value, such as “dollars” or “weight”. Below are some popular Regression algorithms which come under supervised learning:
Linear Regression
- Regression Trees
- Non-Linear Regression
- Bayesian Linear Regression
- Polynomial Regression
How Supervised Learning Works?
Through Supervised learning, models are trained using a labelled dataset, where the model is trained to learn about different types of data. The model is tested using test data (which is a subset of the training set) after the training process is done, and it then predicts the output.
The way that Supervised learning works can be easily understood by the example below:
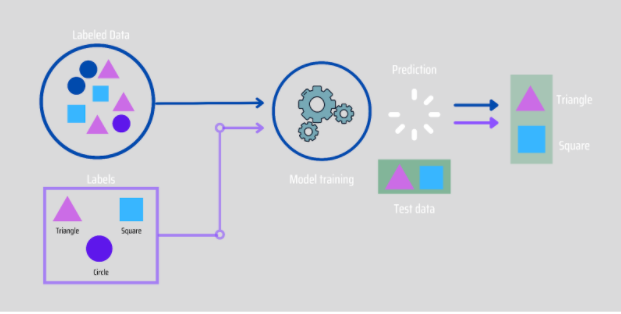
For example, if we have a dataset of different types of colours which includes square, rectangle, triangle, and Polygon. Now the first step is that we need to train the model for each shape.
- If the given shape has four sides, and all the sides are equal, then it will be labelled as a Square.
- If the given shape has three sides, then it will be labelled as a triangle.
- If the given shape has six equal sides then it will be labelled as hexagon.
Now, after training, we test our model using the test set, and the task of the model is to identify the shape.
The machine has already been trained on a variety of shapes, so when it encounters a new shape, it classifies it based on a number of sides and predicts the outcome.
The process of Supervised Learning takes place in some steps:
- First is defining the type of training dataset;
- Collect and gather the labelled training data;
- Split the training dataset into training dataset, test dataset, and validation dataset;
- Determine the input attributes of the training dataset, which should have enough knowledge so that the model can accurately predict the outcome;
- Decide the suitable algorithm for the model, such as support vector machine, decision tree, etc;
- Execute the algorithm on the training dataset. Sometimes we need validation sets as the control parameters, which are the subset of training datasets;
- Evaluate the accuracy of the model by providing the test set. If the model predicts the correct output, which means our model is accurate;
What are the applications of Supervised Learning?
A lot of daily processes that we go through are based on supervised machine learning algorithms. Some of them are listed below:
- Text categorization;
- Face Detection;
- Signature recognition;
- Sales Forecasting;
- Supply and demand analysis;
- Personalizing reviews for goods;
- Weather forecasting;
- Predicting housing prices based on the prevailing market price;
- Stock price predictions.