
An Introduction to Unsupervised Event Clustering
What is Unsupervised Event Clustering?
In general, an event clustering is anything interesting that happened at a specific time. It can be extracted from raw data imported from external sources or data that has been pre processed (e.g. anomaly detection results from metrics). Essentially, an event carries a timestamp and additional information to describe what happened. Because of the sheer quantity of events in an IT Operations monitoring centre, it is not possible for IT Ops personnel to simply display and handle each one of them.
Indeed, different events may be related to each other, which, as a whole, can more fully indicate the underlying cause of a problem. By detecting these relationships, we can provide a more meaningful view of events, as well as assist IT Operations personnel in troubleshooting and finding the cause of a problem.
While modern anomaly detection, event management, and log management tools provide a reasonable means of collecting and processing large volumes of IT operational state information, they do not offer acceptable features for noise reduction and contextualization of the meaningful discrete events. Without machine learning, we are left to developing manual rules that assign meaning and priority to individual events. But too often the volume and variety of event types is intractable, since a given event will mean something different depending on the source or node and the lifecycle of the services that it supports. Additionally, such approaches are very difficult to maintain as underlying systems change and evolve.
Unsupervised event clustering techniques
The nature of IT operational data is such that the volume of metrics, logs, and events available and relevant for monitoring will generate an intractable number of situations to investigate. We have shown that by applying a machine learning workflow, including unsupervised and supervised learning, to filter out and correlate events we can provide a much more useful result that can perform well against traditional threshold-based event management techniques.
There are two options that the unsupervised learning algorithm can be categorized as:
- Clustering: Clustering is a method of grouping the data points into clusters, where data points with most similarities remain into a cluster and have less or no similarities with the objects of another cluster group.
- Association: An association rule is an unsupervised learning method which is used for finding the connection between variables in different databases. It determines the set of data points that occur together in the dataset. This rule is one of the rules that affect marketing strategies, such as people who buy X items also tend to purchase Y items.
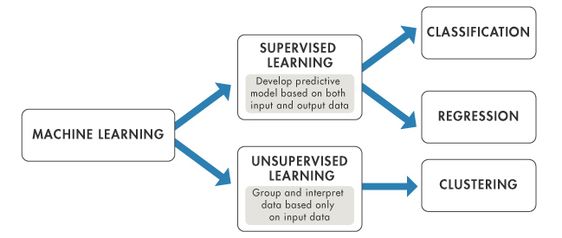
Types of different event clustering methods
The various families of clustering algorithms are:
- Connectivity-based Clustering (Hierarchical clustering)
- Centroids-based Clustering (Partitioning methods)
- Distribution-based Clustering
- Density-based Clustering (Model-based methods)
- Fuzzy Clustering
- Constraint-based (Supervised Clustering
And also, the most common Types of Clustering Algorithms are:
- K-means clustering
- KNN (k-nearest neighbours)
- Hierarchical clustering
- Anomaly detection
- Neural Networks
- Principal Component Analysis
- Independent Component Analysis
- A-priori algorithm
- Singular value decomposition
Stay tuned for our deeper dive into various clustering techniques and the unique problem of time series clustering as well as the importance of the event clustering algorithms in our daily routine!