AIOPS + AUTOMATION: RE-INVENTING THE IT AUTOMATION PLAYBOOK
Read more about from AIOPS + Automation series:
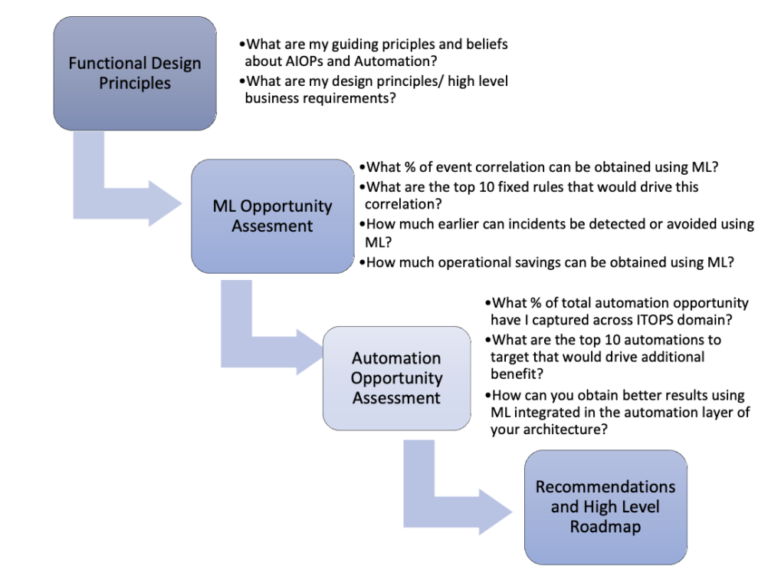
An AIOPS assessment provides a framework for identifying automation candidates by working with individual operations teams to understand where they spend the most time. By collecting process specific data and operational data (tickets, events, and logs) you can apply ML models to test out various improvement targets. For example, you might want to investigate the impact of event clustering on your current incident volumes. The deliverables might look like the below:
When outlining the strategy the project team should identify a set of key guiding principles that establish a strong AIOPS foundation and aligned automation goals, for example:
- We want to learn relationships between events and relationships between logs over time to better correlate them and prioritize them for notification- minimize the need to construct fixed correlation rules;
- We want to learn what the normal behavior of systems look like so that we can only notify operations when abnormal things are happening, thereby reducing noise while minimizing the need to build and maintain thresholds;
- We want to be able to predict Incidents from patterns in abnormal behavior (via anomalies, events, and logs) to group and prioritize operational data presentation (notification and ticketing);
- We want to be able to reinforce each ‘learner’ with feedback from human operators in order to fine tune the learner and teach it new things- systems should get better through human interaction, naturally, without the need for data science or software development for optimization;
- We want to be able to detect configuration changes that have not yet been captured in an approved change request;
- We want to be able to identify problems (from repetitive incidents) early in the problem lifecycle;
- We want to provide a path to near immediate Root Cause Isolation, especially for Incidents with high Impact
AIOPS Design Principles
Along with the business-level guiding principles, the responsible team should collaborate to develop a set of design principles for each functional area through which AIOPS will be integrated. The following are some examples of design principles:
GENERAL
- The architecture should maximize the available information for training learning algorithms so that each region can take advantage of relevant experience from other regions.
- Predictions should be based on operational data.
- Unsupervised learning algorithms should learn in-line (not require a full pass through the historical data to learn new patterns).
- Models should learn from human feedback in-line, i.e. without requiring parameter tuning or feature engineering (i.e a. data scientist).
- The architecture should support arbitrary unsupervised and supervised learning algorithms
FAULT/EVENT MANAGEMENT
- Unsupervised event and log clustering should learn patterns across tools / domains- systems using different models for clustering will have a different meaning
PERFORMANCE MANAGEMENT
- Unsupervised anomaly detection should learn patterns across tools / domains- systems using different models for clustering will have a different meaning
CONFIGURATION MANAGEMENT
- Learning algorithms should be able to take advantage of special, topological relationships of objects in order to maximize performance and deliver root cause inferences.
INCIDENT MANAGEMENT
- Align Major incidents to services and the right resources at the right time.
- Enable consistent and reliable incident data for on-going ML training.
- Provide context from event monitors, anomalies & meta-data for accelerated MTTR.
CHANGE MANAGEMENT
- Accurately evaluate risk based on historical context.
PROBLEM MENAGEMENT
- Reliably provide root cause details for accurate problem resolution.
- Enable & enforce feedback loop from known errors & problem resolution to prevent future incidents.
OPERATIONAL KNOWLEDGE MENAGEMENT
- Leverage ALL classified learning(automated and manual) for ML training.
RUNBOOK AUTOMATION
- Automate preventative tasks for pre-Incidents.
- Allow for scripting for resolution, not just service restoration.
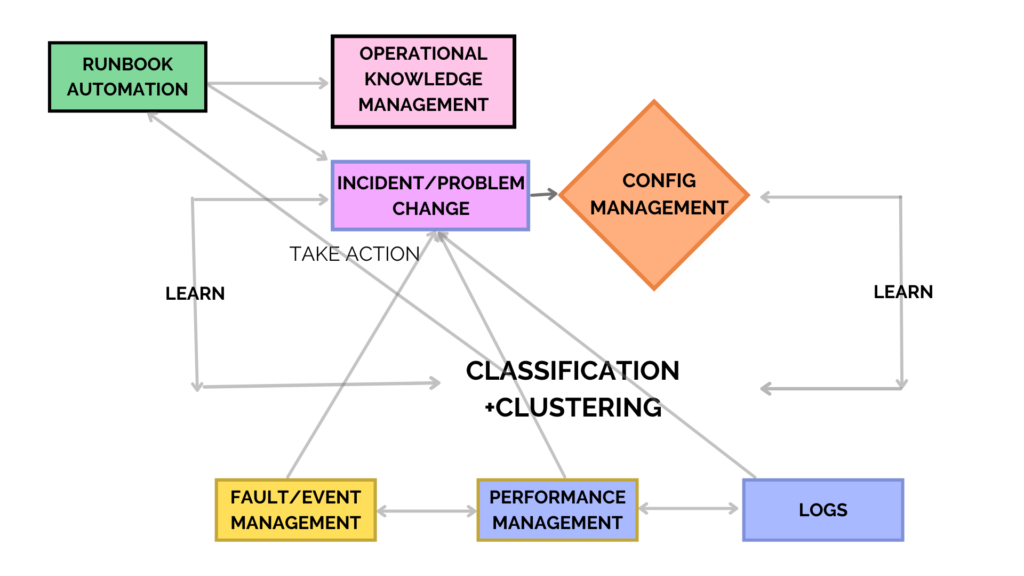
An example of a logical architecture might look like the visualization below: