Part II: AIOps 2.0 - The Evolution of Correlation
Level 1: Rule-based correlation
Rule-based correlation uses traditional correlation logic to analyze information collected in real time. This correlation takes all logs, events, and network flows that are correlated together along with contextual information such as identity, roles, vulnerabilities, and more—to detect patterns indicative of a larger threat. There are mainly two types of rules: network topology based rules and service model based rules.
Figure 1.1: Simple Topology Example
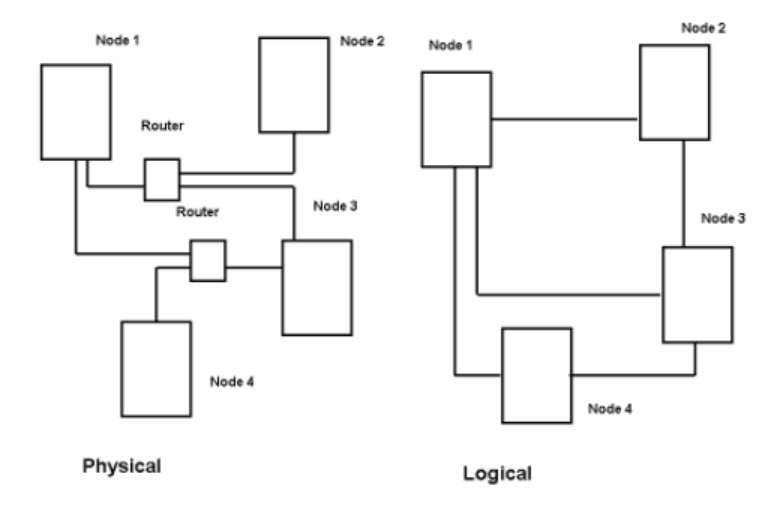
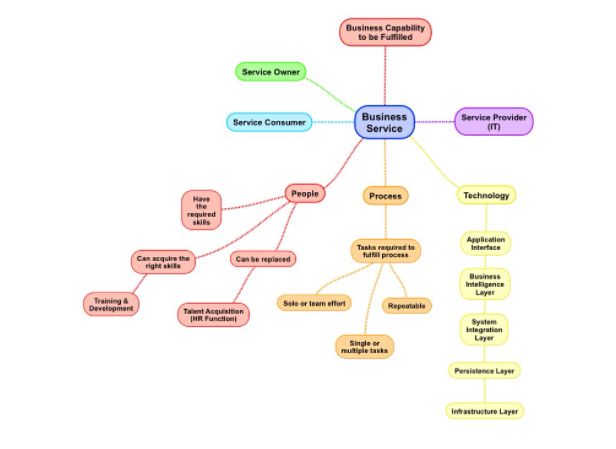
Figure 1.2: Simple Business Service Model Template
For the network topology based rules, firstly, we must build an inventory of all network devices and subcomponents. Secondly, we must draw edges between each component connected to the network or to some layer of the OSI protocol stack. Once those edges are defined, we can build the rules to group events if their originating devices, for instance, are within 2 hops of each other.
Rules specific to particular types of devices and parts of the network have to be developed and managed over time (Fournier-Viger et al., 2021). Certainly, there are pros and cons to using this rule. Unfortunately for us, the cons of this particular rule outweigh the pros.
Pros:
- Easy to impose correlation logic if the behavior of the system is deterministic
- For incidents whose root cause is a network failure, a rule based on inference applied to the topology (simple connectivity inference) of the network will often suffice for accurate grouping of the events related to that root failure.
Cons:
- Difficult to accurately inventory ever-evolving, large networks- leading to reduced efficacy and increased skepticism. A statically defined Configuration Management Database (CMDB) has a high rate of entropy.
- Difficult to accurately map topological relationships across network devices. Network discovery tools can help with this (as well as the entropy problem) but they are very difficult and expensive to implement across large complex networks and the complex configurations required are very brittle over time as the network evolves. This leads to high maintenance costs and usually a reduction of scope that minimizes the efficacy of the CMDB.
- Limited generalization of rules leading to many static rules over time. For example, the causal relationship between 2 directly connected network devices (an app server and a database server) might make sense in that if a node-down event comes from both the server and the database, it probably makes sense to group them. Rules that effectively group more than just directly connected devices are difficult to construct, leading to a limitation in the amount of event compression that can be realized.
- High implementation costs to implement the discovery tools and the CMDB
- High development costs to build and deploy static correlation rules
- High maintenance costs to effectively maintain the CMDB, the topology, and the static correlation rules.
- Cost and complexity can lead to minimally effective deployments even after large time and software expenses
On the other hand, service model based rules require that services are defined in a way that event metadata can be associated with a particular service. This metadata may be node information or other logical components of the service. Similar to a network topology, the service models must map common edges across these logical components. And similarly to topology based rules, the cons for this rule also outweigh the pros.
Pros:
- Easy to impose correlation logic if the behavior of the system is deterministic
- The rule development can be prioritized such that the most important services are defined first
Cons:
- Difficult to accurately define services across a large and complex business in a way that makes it reasonable to map events to those components of the model.
- Difficult to accurately map service relationships across network devices.
- Limited generalization of rules leading to many static rules over time. Service models are typically ‘all-or-nothing’ such that events that match a service model are grouped together, and events that don’t are not. But services often share the same infrastructure components at different layers of the network and so disambiguating concurrent incidents is difficult.
- High implementation costs to work with each business unit to define service models
- Long deployment times
- High maintenance costs to effectively maintain the service relationships- specialized skills are required but business unit SMEs might be reluctant to take on the work and training required.
- Cost and complexity can lead to minimally effective deployments even after large time and software expenses
- Cost and complexity can lead to minimal compression of the event stream, where only the most important services are effectively defined.
In general, rules based correlation can provide only limited compression of the event stream, but with sufficient development time, can provide for moderately accurate correlation.